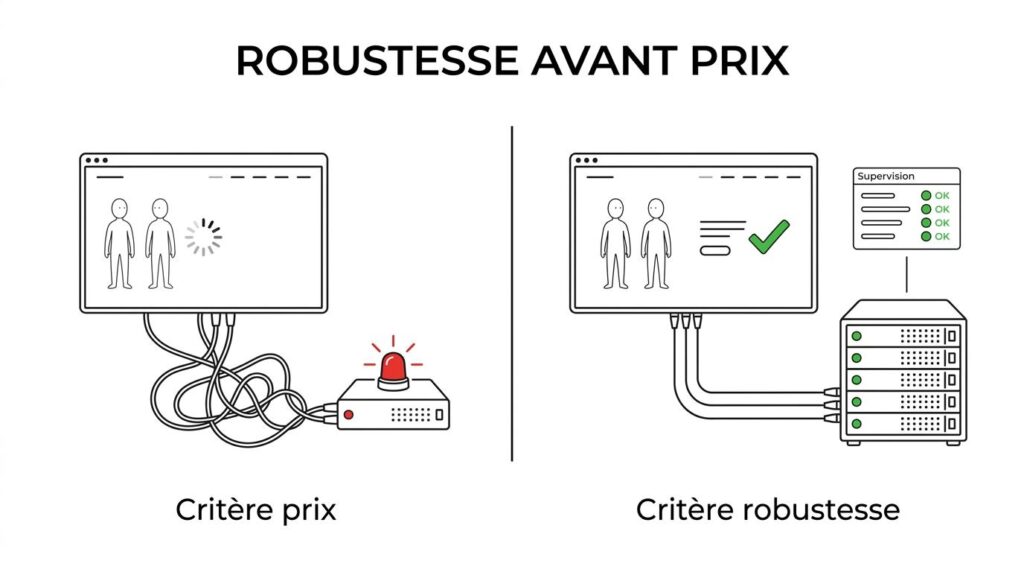
Il existe des milliers de façons de classer les données, mais nous avons choisi la meilleure : la « IA classification des données ». Dans cet article, nous allons explorer cette méthode innovante et efficace pour organiser vos informations de manière intelligente et percutante. Préparez-vous à plonger dans le monde fascinant de la classification des données avec une touche d’humour et beaucoup de créativité. Vous ne verrez plus jamais vos données de la même manière après avoir découvert la « IA classification des données » !
Les données sont aujourd’hui omniprésentes dans notre quotidien, et leur classification est un enjeu majeur dans le domaine de l’intelligence artificielle. L’IA a révolutionné la façon dont nous traitons et analysons ces données, ouvrant ainsi de nouvelles perspectives et possibilités.
Dans le vaste monde de l’IA, la classification des données occupe une place centrale. En effet, il s’agit de regrouper des données similaires en catégories ou classes distinctes, permettant ainsi de les organiser de manière cohérente et structurée.
Grâce à des algorithmes sophistiqués, l’IA est capable d’analyser de grandes quantités de données et de les classer de manière automatique et efficace. Cela permet aux entreprises de prendre des décisions éclairées et d’optimiser leurs processus, tout en gagnant un temps précieux.
Des questions ? N’hésitez pas, nous sommes là pour vous aider !
| Avantages de la classification des données en IA: |
|---|
| Optimisation des processus |
| Prise de décision éclairée |
| Gain de temps précieux |
Les différents types de données à classifier
Il existe une variété de types de données à classifier en intelligence artificielle. Chaque type de donnée a ses propres caractéristiques et exigences spécifiques pour être correctement catégorisé. Voici quelques-uns des principaux types de données à prendre en compte :
-
- Données numériques : ces données sont sous forme de nombres, ce qui facilite souvent leur traitement et leur classification.
-
- Données textuelles : ces données sont constituées de mots ou de phrases, nécessitant des techniques de traitement du langage naturel pour être classifiées efficacement.
-
- Données d’image : ces données sont composées de pixels et nécessitent des algorithmes de vision par ordinateur pour être analysées et classifiées.
-
- Données temporelles : ces données sont associées à des horodatages et des séquences chronologiques, ce qui peut nécessiter des méthodes spécifiques de classification temporelle.
Chaque type de donnée présente ses propres défis et opportunités en matière de classification. Il est essentiel de choisir les bonnes techniques et algorithmes en fonction du type de données à traiter pour obtenir des résultats précis et fiables en intelligence artificielle.
| Type de Donnée | Techniques de Classification |
|---|---|
| Données Numériques | Classification Supervisée |
| Données Textuelles | Classification Non Supervisée |
| Données d’Image | Réseaux Neuronaux Convolutifs |
| Données Temporelles | Séries Temporelles |
En conclusion, la classification efficace des différents types de données en intelligence artificielle est essentielle pour la prise de décision et la résolution de problèmes complexes. Il est important de comprendre les particularités de chaque type de donnée et d’appliquer les techniques de classification appropriées pour obtenir des résultats précis et fiables.
Que vous travailliez avec des données numériques, textuelles, d’image ou temporelles, l’IA offre un large éventail d’outils et de méthodes pour vous aider à classifier efficacement vos données et à en tirer des insights précieux pour votre entreprise ou votre projet.
L’importance de la classification des données
La classification des données est une étape essentielle dans le processus d’analyse et d’interprétation des informations. En effet, sans une classification adéquate, il devient difficile de structurer et d’organiser les données de manière efficace. Cela peut conduire à des analyses incohérentes et à des prises de décisions erronées.
Grâce à l’intelligence artificielle, la classification des données est devenue plus précise et plus rapide que jamais. Les algorithmes d’apprentissage automatique sont capables d’identifier des schémas et des tendances dans les données qui échappent souvent à l’œil humain. Cela permet aux entreprises de prendre des décisions éclairées et de rester compétitives sur le marché.
Une classification efficace des données permet également d’améliorer la qualité des prédictions et des recommandations générées par les systèmes d’intelligence artificielle. En classant correctement les données, on s’assure que les modèles d’IA sont capables de fournir des insights pertinents et précieux pour les utilisateurs.
En résumé, la classification des données est un pilier fondamental de l’intelligence artificielle. Sans une classification précise et structurée, les systèmes d’IA ne pourraient pas fonctionner de manière optimale et les entreprises perdraient un avantage concurrentiel crucial. Il est donc essentiel d’accorder une attention particulière à la classification des données pour garantir la fiabilité et la pertinence des informations analysées.
Les défis de la classification des données
sont nombreux et complexes dans le domaine de l’intelligence artificielle. L’un des principaux défis est de trouver des algorithmes efficaces pour trier et organiser de grandes quantités de données de manière précise et rapide.
Certaines des difficultés auxquelles les chercheurs sont confrontés incluent :
-
- La diversité des types de données à classifier.
-
- Le manque de données de haute qualité pour entraîner les modèles de classification.
-
- La nécessité de maintenir la confidentialité des données sensibles tout en les classant.
Dans ce contexte, l’utilisation de techniques avancées d’apprentissage automatique telles que les réseaux de neurones profonds peut aider à surmonter ces défis en permettant aux systèmes informatiques de reconnaître des schémas complexes dans les données et d’améliorer les performances de classification.
| Avantages | Inconvénients |
|---|---|
| Amélioration de la précision des classifications. | Nécessite une grande quantité de données pour l’entraînement. |
| Automatisation du processus de classification. | Complexité accrue des modèles. |
En fin de compte, la recherche et le développement continus dans le domaine de l’IA classification des données sont essentiels pour relever ces défis et tirer le meilleur parti des avantages de la classification des données pour améliorer les décisions et les processus dans divers domaines tels que la santé, la finance et la logistique.
Les méthodes et techniques de classification disponibles
peuvent sembler complexes au premier abord, mais ne vous inquiétez pas, l’IA est là pour vous faciliter la tâche. Grâce à des algorithmes sophistiqués, vous pouvez désormais classer vos données de manière efficace et précise.
L’une des méthodes les plus courantes est la classification supervisée, où le modèle apprend à partir de données étiquetées pour prédire la classe d’un nouvel échantillon. Cette approche est particulièrement utile lorsque vous disposez d’un ensemble de données bien balancé et étiqueté.
En revanche, la classification non supervisée consiste à regrouper les données en fonction de leurs similarités, sans utiliser d’étiquettes. C’est un excellent moyen de découvrir des schémas cachés dans vos données et de segmenter votre public en groupes homogènes.
Parmi les techniques les plus populaires, on retrouve les arbres de décision, les réseaux de neurones, et les machines à vecteurs de support. Chacune de ces méthodes offre des avantages uniques, et il est essentiel de choisir la plus adaptée à vos besoins spécifiques. N’ayez pas peur d’expérimenter et de trouver la méthode qui fonctionne le mieux pour vous.
Recommandations pour une classification efficace des données
Il est essentiel de bien classer les données pour garantir une utilisation efficace de l’intelligence artificielle. Voici quelques :
Utiliser des catégories claires et précises : Assurez-vous que les catégories que vous créez sont distinctes et bien définies. Cela facilitera la tâche de l’algorithme d’apprentissage automatique pour classer correctement les données.
Éliminer les doublons : Avant de classifier vos données, assurez-vous de supprimer les doublons. Cela permettra d’éviter toute confusion et garantira que chaque donnée est correctement placée dans sa catégorie appropriée.
Utiliser des métadonnées pertinentes : Les métadonnées sont essentielles pour une classification efficace des données. Assurez-vous d’inclure des informations pertinentes telles que la date de création, l’auteur, le type de données, etc.
Effectuer une validation régulière : Pour garantir la précision de la classification des données, il est important de réaliser régulièrement des vérifications et des validations. Cela permettra de détecter et de corriger rapidement toute erreur de classification.
Conclusion et perspectives pour l’avenir
Après avoir exploré les différentes méthodes de classification des données par l’IA, il est clair que les possibilités sont infinies. L’IA offre des avantages considérables en termes d’efficacité et de précision dans la catégorisation des données, ce qui peut avoir un impact significatif sur de nombreux secteurs d’activité.
En examinant de plus près les résultats obtenus à partir des différents modèles d’apprentissage automatique, il est évident que la qualité des données entrantes joue un rôle crucial dans la précision des classifications. Il est donc impératif pour les entreprises de s’assurer que leurs données sont propres, précises et bien structurées pour garantir des résultats fiables.
Dans un avenir proche, nous pouvons nous attendre à voir une évolution constante dans le domaine de l’IA et de la classification des données. Les avancées technologiques ne cessent de repousser les limites de ce que l’IA peut accomplir, ouvrant la voie à de nouvelles applications passionnantes et innovantes.
En conclusion, l’IA a clairement révolutionné la manière dont nous traitons et organisons les données. Avec une attention accrue portée à la qualité des données et une innovation continue dans le domaine, nous pouvons nous attendre à des avancées majeures dans la classification des données et à des perspectives prometteuses pour l’avenir.
En conclusion, classer les données peut sembler fastidieux et compliqué, mais c’est en réalité un moyen efficace d’organiser l’information et de faciliter son utilisation. Alors n’hésitez pas à vous lancer dans l’aventure de l’IA classification des données, vous verrez que c’est bien moins effrayant qu’un labyrinthe de dossiers en désordre sur votre bureau ! À vos marques, prêts, classez !
Des questions ? N’hésitez pas, nous sommes là pour vous aider !